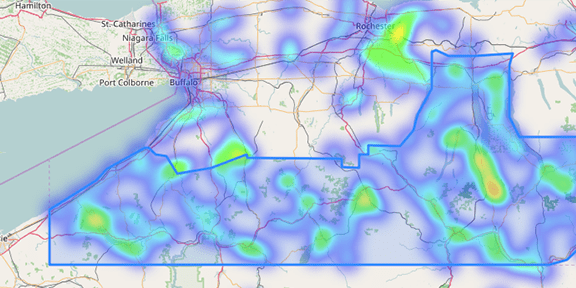
How to make an interactive geographic heatmap using Python and free tools. This example uses Folium, a Python wrapper for leaflet.js maps and geopandas. Read More

Data Science and Business Consulting Services by Mike Cunha
I help clients use data to achieve their goals. From data collection, processing, and analysis, to communicating the results and deploying data-driven products to production.
I can help you apply ML, deep learning, and statistics to your business processes: classification, A/B testing, prediction, recommendation, sentiment, search, natural language processing, entity resolution and more.

Many clients have a slow but critical reporting process that can be sped up by automating manual and Excel workflows and by making the output more versatile. Common things I deliver for these types of projects are data processing pipelines, automated reporting, and dashboards. Read More about common reasons clients hire me or take a look at an example web interface I have built.
For some clients, I serve as an on-call partner by providing data science and data engineering technical expertise and advice to test new strategies on a regular basis, diagnose problems as they appear, and help companies that are just beginning to build out their data team.
I also offer one-on-one mentoring and small group sessions on topics like data visualization, data cleaning, automated reporting, machine learning, and hypothesis testing upon request. I can give crash courses on using tools like python for data science, Jupyter, and Tableau as well.

I am currently taking on new clients, reach out to me for a free consultation.
Some common problems and opportunities I can help you with:
Having problems scaling an existing data-related process? Spreadsheets getting too complicated? Or maybe you have so much data you don't know where to start. I automate time-consuming repetitive tasks and help you decide which opportunities to pursue now, and in the long-term. I can also help you build tools to search through your data, whether you are an analyst bogged down with slow SQL queries or an HR specialist unable to locate a form on your intranet.
 Many businesses struggle with poor data quality, from sole proprietors to multi-national corporations. It's hard to
make informed decisions when you can't get what you need, when you need it. I help clients assess data quality and
how it's impacting their business, improve it with better data collection practices, and make the most of what
they already have. Perfect data isn't practical; often times great value can be had from data that's
just good enough.
Many businesses struggle with poor data quality, from sole proprietors to multi-national corporations. It's hard to
make informed decisions when you can't get what you need, when you need it. I help clients assess data quality and
how it's impacting their business, improve it with better data collection practices, and make the most of what
they already have. Perfect data isn't practical; often times great value can be had from data that's
just good enough.
Some obvious questions can be very difficult to answer: What price should I charge? Which combination of products in a bundled offer will yield the most profit? Which part of my inventory can I liquidate to free up the most cash with the least risk? These are all questions I can help you answer.
Thanks to widely available open source libraries and cheap cloud computing you don't need to hire a team of deep learning experts or buy an expensive proprietary appliance to benefit from some of the unstructured data you probably already have: customer feedback, blog posts, documents, images, audio, or social media posts. Software that can automatically summarize, classify and act on unstructured data is not just for Fortune 500 companies. I also have experience using domain-specific data to produce custom models that perform better at specific tasks than the widely available machine learning APIs offered by major cloud providers.
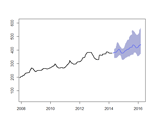 Reporting tells you what happened, real-time reporting tells you what is happening, and
forecasting tells you what could happen. By training a predictive model on historical data and conducting
time-series analyses, I can help you make informed decisions before your normal reporting would usually be available.
Reporting tells you what happened, real-time reporting tells you what is happening, and
forecasting tells you what could happen. By training a predictive model on historical data and conducting
time-series analyses, I can help you make informed decisions before your normal reporting would usually be available.
Some decisions on how to interact with your customers have to be made, regardless of available data quality. Validating the assumptions you make about your customers can be critical. I can help you learn more about your customers and validate the assumptions you have already made. I have experience analyzing unstructured text like customer reviews, chat transcripts, and comments; mining log files for pain points and buying patterns; segmenting them into personas; scoring leads; modeling churn and optimizing retention.
Each department has its own database, for its own purposes, often undocumented outside of that department. How do you know if the 'John Smith' in your marketing database is the same customer as the 'John Smith' in your sales database? I have experience partnering with in-house teams to assist in combining disparate schemas, building data dictionaries, ETLs, and matching and merging millions of contact records.
![]() There has been an explosion of data-related vendors and services in the past few years, and likewise, there
is no shortage of salespeople eagerly telling you how you're a perfect fit for their one-click solution. I
provide clients with technical advice that allows them to see through the hype and find the right tools and
services for their business. I also have worked with several smaller customers looking for advice on their
fist data science hires and efforts.
There has been an explosion of data-related vendors and services in the past few years, and likewise, there
is no shortage of salespeople eagerly telling you how you're a perfect fit for their one-click solution. I
provide clients with technical advice that allows them to see through the hype and find the right tools and
services for their business. I also have worked with several smaller customers looking for advice on their
fist data science hires and efforts.
For clients that don't have access to enterprise-level tools I have built custom lightweight solutions. Contact me for access to demo.alcidanalytics.com to see an example of a secure web interface to an automated data pipeline along with a d3.js powered interactive dashboard.
Custom, interactive, in the browser. Click the GIF below to see an example.
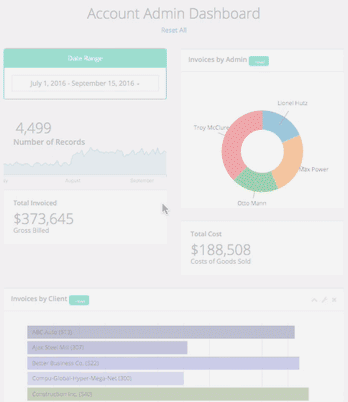 GIF
GIFCustomized, easy to use interfaces for running complex automated processes.
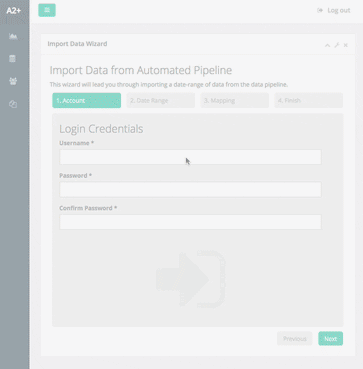 GIF
GIFConsistent interface across screens allows clients to access the solutions I build on almost any device.


Apps adhere to security best practices and can range from being public facing to a private extension of a client's intranet over VPN, complete with role-based user management.
Display an Excel-like view of data underlying a dashboard and edit it in-place.

Not every project needs an app or a web interface, there are one-off analyses, python packages, productionized models, and other software too.
Jupyter notebooks allow me to show a client exactly how I performed each step of an analysis and tailor the explanation to the client's technical ability. It is an important tool I use to make data accessible to a wide variety of teams within a client's organization. Decision makers can use them to see specific results and visualizations, while hiding complex details. The detail is easily revealed allowing the client's in-house team to quickly verify the results; even one-off analyses need to be reproducible and will come version controlled with documentation.
For projects that involve more software engineering effort than one-off analyses such as real-time recommenders, classifiers, and ETL’s, I like to adhere to additional best practices to ensure the deliverables are production-ready and maintainable even if I’m not the one doing the deploy. Tests, doc-strings, consistent formatting, logging, and refactoring code into pip installable python packages where appropriate are the norm. Code Sample
Latest posts and guides from the Alcid blog.
How to make an interactive geographic heatmap using Python and free tools. This example uses Folium, a Python wrapper for leaflet.js maps and geopandas. Read More
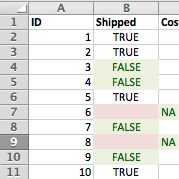
Avoiding these bad habits will make it easier for others to work with your spreadsheets and make it easier for you to update and maintain them. Read More
How to prettify source code snippets with Pygments syntax highlighting on a bootstrap-powered site. Fix CSS conflicts between Pygments and bootstrap. Read More
I am a data scientist based out of the Rochester, NY area working as a freelance consultant since 2015 and in data science since 2013. I have a MSc in Natural Resource Management from HSU and a BS in Biology from SUNY ESF. A seabird biologist turned data scientist, I am most interested in applied machine learning, NLP, and data science ethics. The following is a summary of my experience, skills, and some of the tools I'm comfortable using:
